

| 제 42강) 정렬 알고리즘 - 힙 정렬2 |
오늘은 정렬 알고리즘의 세번째 시간으로 "삽입 정렬"에 대해서 알아봅니다.
기본적으로 삽입 정렬은 배열에서 사용합니다.
오늘은 힙(Heap)에 대해서 알아볼겁니다.
| 힙(Heap) 이란 |
힙은 지난 시간에 배운 "이진트리(binary tree)" 중에서도 "완전 이진트리(complete binary tree)"를 기반으로 한 자료구조입니다.
자료 구조 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 자료구조(資料構造, 영어: data structure)는 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다.[1][2][3] 더 정확히 말해, ��
ko.wikipedia.org
힙은 다음과 같은 조건을 만족합니다.
- A가 B의 부모노드(parent node) 이면, A의 키(key)값과 B의 키값 사이에는 대소관계가 성립한다.
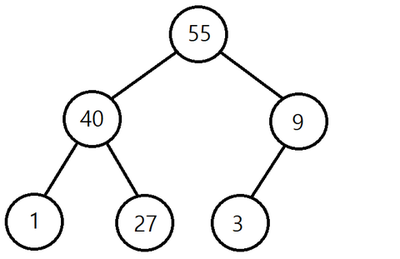
즉, 위의 사진처럼 부모노드는 자기의 자식노드보다 항상 큰 값을 가지고 있게 됩니다.
(min heap의 경우에는 그 반대가 됩니다. 기본적으로는 max heap입니다.)
(min heap: 부모가 자식보다 항상 작다.)
(max heap: 부모가 자식보다 항상 크다.)
여기서 대소 관계는 오직 부모와 자식간에만 성립하며 자식과 자식사이에는 성립하지 않습니다.
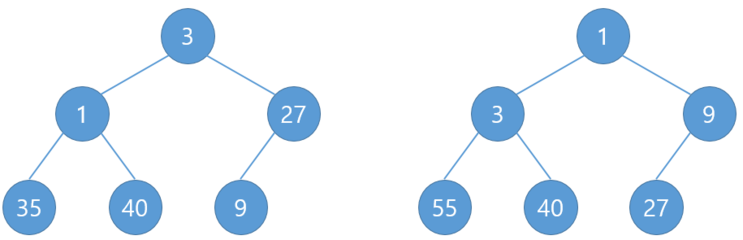
그래서 위의 힙은
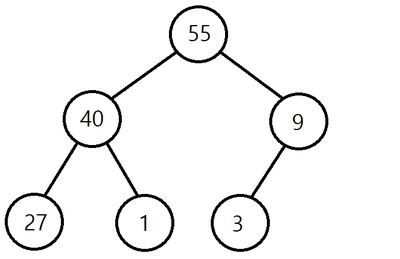
이렇게도 될 수 있습니다.
| 최대 힙(max heap) |
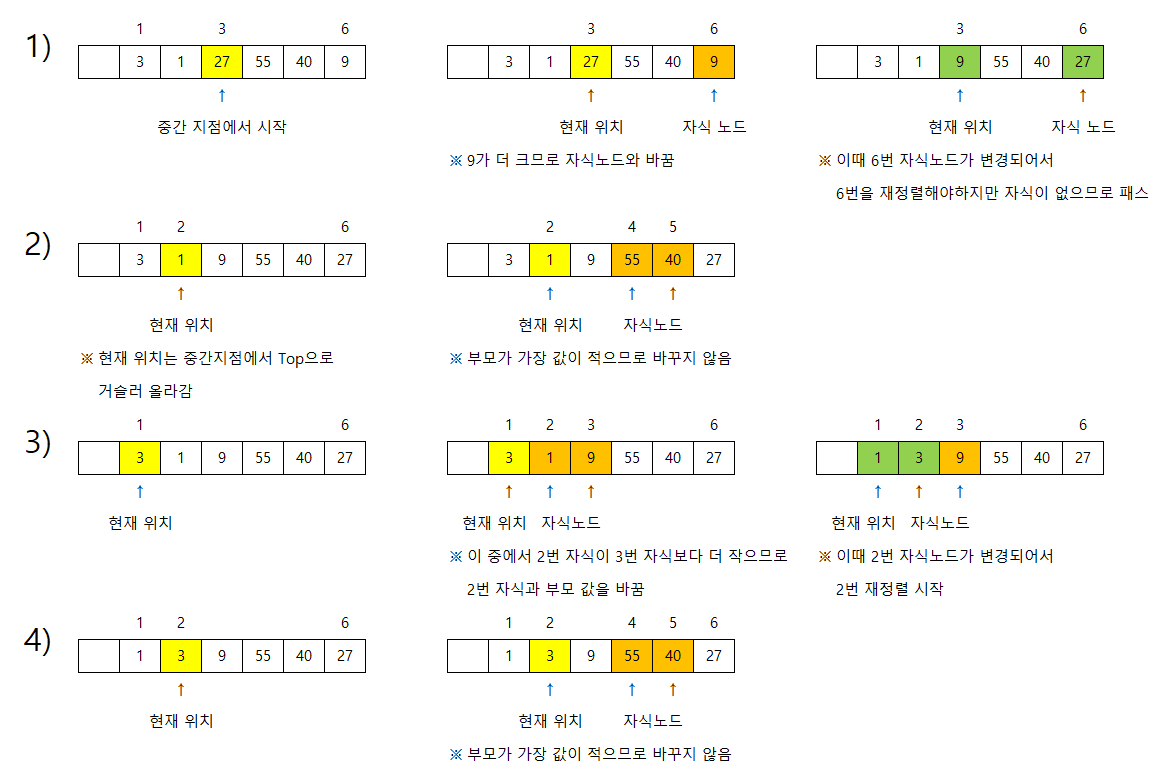
그럼 최대 힙으로 한 번 만들어봅시다.
하지만 그 전에 어떻게 구성하는지 먼저 알아보아야겠죠?
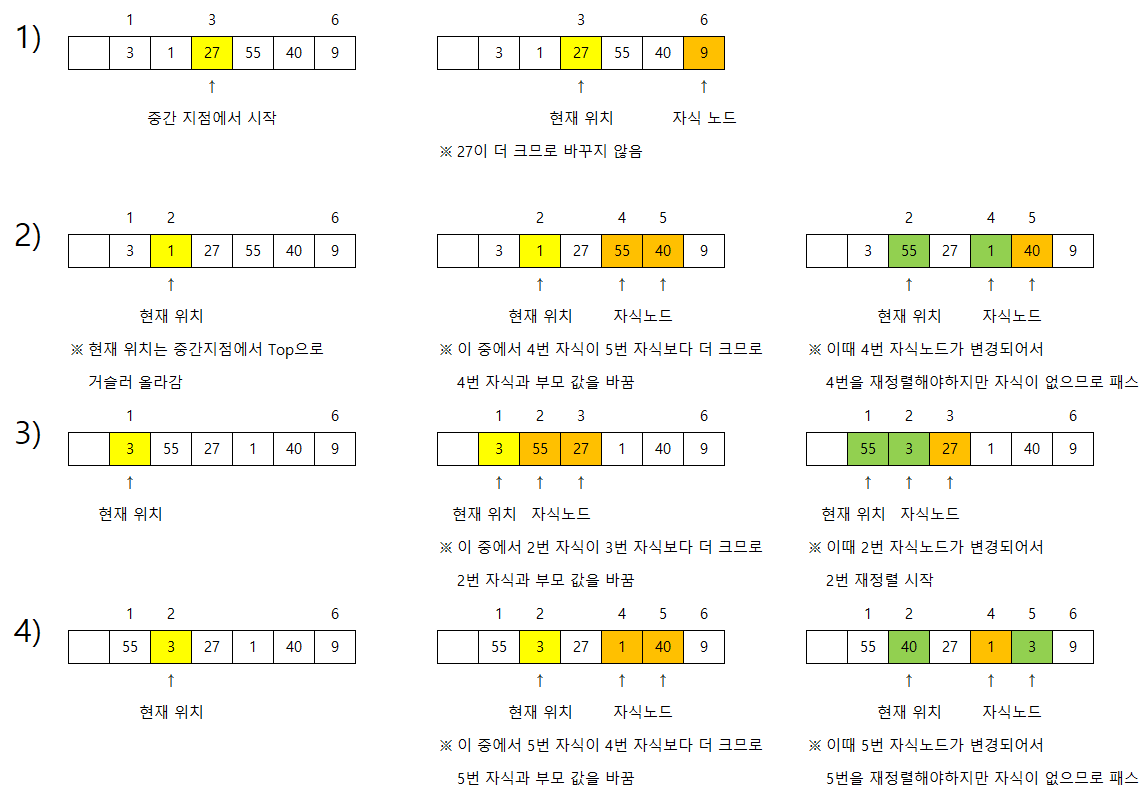
(잘 안보이시면 눌러서 보시면 됩니다.)
항상 힙의 중간 지점부터 시작을 합니다.
그렇게 하여 자식들과 비교연산을 하여 자식들 중 가장 큰 값과 자신을 비교하여 스왑을 하게 됩니다.
스왑된 값은 그 지점에서 자식이 있다면 다시 재정렬에 들어가게 됩니다.
위와 같이 정렬을 하게 되면
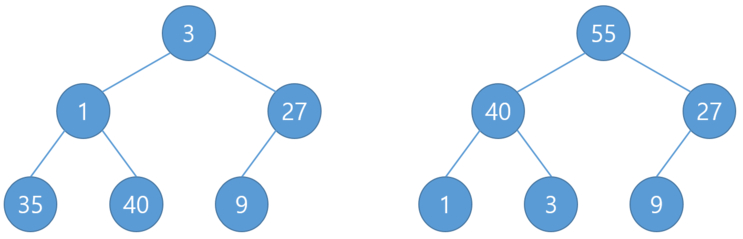
이렇게 최대 힙으로 정렬이 됩니다.
| 최소 힙(min heap) |
최소 힙은 최대 힙을 구성하기 위한 조건을 반대로 이용하면 됩니다.
| 최대 힙 구현 |
이제 최대 힙을 구현하여 봅시다.
먼저 힙 소스는 지난 시간의 것을 그대로 가져와서 여기에 최대 힙으로 만들어주는 함수를 더하기만 할겁니다.
(이때 순회하는 함수는 전부 뺐습니다.)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <Windows.h> // Sleep 함수를 위한 헤더파일
#define MAX 100 // 배열의 크기
#define YES 1
#define NO 0
// 트리 구조체
typedef struct _TREE
{
int arr[MAX + 1];
int count;
} Tree;
// 왼쪽 자식의 위치를 계산하는 인라인 함수
inline int leftChild(int index)
{
return index * 2;
}
// 오른쪽 자식의 위치를 계산하는 인라인 함수
inline int rightChild(int index)
{
return index * 2 + 1;
}
// 삽입(항상 맨 끝에 삽입)
void insert(Tree* tree, int value)
{
if ((*tree).count < MAX)
{
(*tree).count++;
(*tree).arr[(*tree).count] = value;
}
else
printf("오류 : 배열 포화 상태");
}
// 두 위치의 값을 바꿈
void swap(Tree* tree, int pos1, int pos2)
{
int tmp = tree->arr[pos1];
tree->arr[pos1] = tree->arr[pos2];
tree->arr[pos2] = tmp;
}
// 최대 힙 함수
// tree: 트리
// pos: 대상 위치
// isSub: 자식 노드와 부모 노드가 스왑된 이후의 최대힙 재계산인지 판단
// YES = 재계산
// No = 일반계산
void maxHeap(Tree* tree, int pos, int isSub)
{
int bigPos = 0; // 자식 노드 중 가장 큰 노드의 위치
int leftPos = 0; // 자식 노드의 왼쪽 노드 위치
int rightPos = 0; // 자식 노드의 오른쪽 노드 위치
// 현재 위치가 0이면 종료
if (pos == 0)
return;
// 왼쪽 자식 노드 위치 계산
leftPos = leftChild(pos);
// 왼쪽 자식 노드가 존재 한다면
if (leftPos <= tree->count)
{
// 오른쪽 자식 노드 위치 계산
rightPos = rightChild(pos);
// 오른쪽 자식 노드도 존재 한다면
if (rightPos <= tree->count)
{
// 큰 노드의 위치를 계산하여 bigPos에 저장
if (tree->arr[leftPos] > tree->arr[rightPos])
bigPos = leftPos;
else
bigPos = rightPos;
}
// 오른쪽 자식 노드가 없다면
// 왼쪽 자식 노드가 자식 노드 중에서 가장 큰 노드
else
bigPos = leftPos;
// 가장 큰 자식 노드와 부모 노드의 대소비교
if (tree->arr[pos] < tree->arr[bigPos])
{
// 부모 노드보다 크면 부모 노드와 해당 자식 노드 스왑
swap(tree, pos, bigPos);
// 스왑되어 바뀐 자식 노드 위치에서 다시 최대 힙 연산 수행
maxHeap(tree, bigPos, YES);
}
}
// 왼쪽 자식 노드가 존재하지 않으면 오른쪽 자식 노드도 존재하지 않음
// 그러므로 종료
else
return;
// 재계산이 아닐경우 다음 부모 노드로 넘어감
if (isSub == NO)
maxHeap(tree, pos - 1, NO);
}
// 트리를 출력하는 함수
void printTree(Tree* tree)
{
printf("arr: ");
for (int i = 1; i <= tree->count; i++)
{
printf("%d", tree->arr[i]);
if (i == tree->count)
printf("\n");
else
printf(", ");
}
}
int main(void)
{
Tree tree;
const int LENGTH = 18;
tree.count = 0;
srand((unsigned int)time(NULL));
for (int i = 1; i <= LENGTH; i++)
{
insert(&tree, rand() % 30 + i);
Sleep(100); // 최대한 중복값이 생기지 않도록 랜덤값 생성에 텀을 줌
}
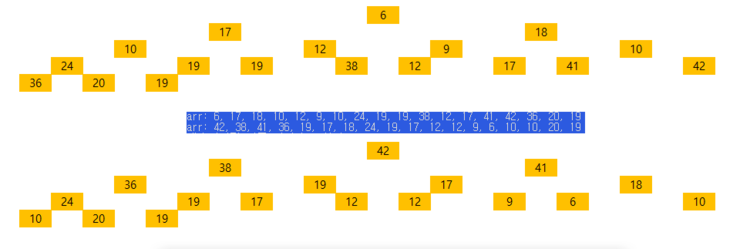
printTree(&tree);
maxHeap(&tree, LENGTH / 2, NO); // 시작 지점은 절반 지점
printTree(&tree);
return 0;
}이때 주의해야 할 점은 maxHeap 계산에서 두 자식이 존재할 때 왼쪽 자식은 오른쪽보다 커야만 해당 자식이 bigPos로 선정되며 오른쪽 자식과 왼쪽 자식의 값이 같을 경우에는 왼쪽 자식으로 bigPos가 선정되게 했습니다.
(이 부분은 사실 상관이 없습니다. 무조건 부모 노드가 자식노드보다 크기만 하면 됩니다.)
오늘은 힙이라는 자료구조에 대해서 배웠습니다.
다음 시간에는 이 힙을 가지고 힙 정렬에 대해서 배워봅시다.
'Study > C언어' 카테고리의 다른 글
| 처음하시는 분들을 위한 C언어 기초강의 시즌2 - 44 [정렬 알고리즘(셀 정렬, Shell sort)] (1) | 2020.05.25 |
|---|---|
| 처음하시는 분들을 위한 C언어 기초강의 시즌2 - 43 [정렬 알고리즘(힙정렬3 - 힙정렬)] (0) | 2020.05.25 |
| 처음하시는 분들을 위한 C언어 기초강의 시즌2 - 41 [정렬 알고리즘(힙정렬1 - 이진트리)] (0) | 2020.05.25 |
| 처음하시는 분들을 위한 C언어 기초강의 시즌2 - 40 [정렬 알고리즘(퀵 정렬)] (0) | 2020.05.25 |
| 처음하시는 분들을 위한 C언어 기초강의 시즌2 - 39 [정렬 알고리즘(합병 정렬)] (0) | 2020.05.25 |